Capítulo 1 Manejo de Datos Hidrometeorológicos
1.1 Objetivo de la práctica
Manejar registros de precipitación en intervalos de 5 minutos para obtener información en distintas escalas temporales mediante la agregación de datos hidrometeorológicos
1.2 Resultados de la práctica
Agregar y transformar variables hidrológicas en distintas escalas temporales, aplicando la metodología adecuada para su análisis y procesamiento de datos.
1.3 ¿Que datos usaremos en la clase?
Para la práctica se utilizarán datos de precipitación registrados en la estación climatológica Rumipamba, identificada con el código C4. Esta estación mide la precipitación con una resolución temporal de 5 minutos, lo que significa que cada registro corresponde a la cantidad de precipitación acumulada en ese intervalo de tiempo.
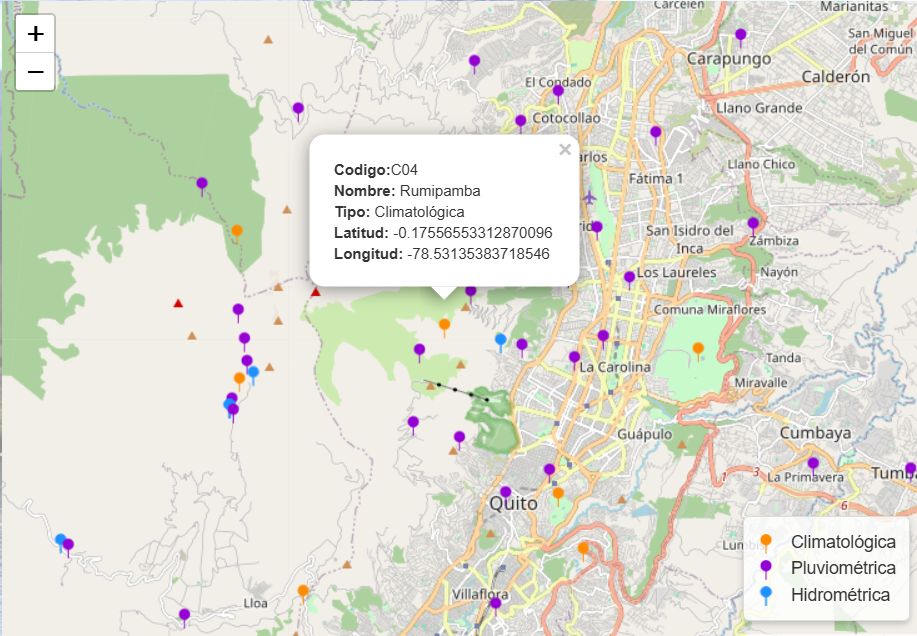
Figure 1.1: Ubicación de la Estación C04
Visualizemos los datos con los que contamos
#Carguemos y almacenemos el archivo
C4<- read.csv("./Documentos/EPMAPS-C04-RUMIPAMBA_Precipitación-Subhorario.csv")
#¿Cuantos datos tenemos?
nrow(C4)
#> [1] 1938620Observemos que datos tenemos, la serie de datos es muy extensa por lo que visualizaremos los 6 primeras filas y posteriormente un resumen estadístico de los datos
head(C4)
#> Fecha Valor..mm.
#> 1 2000/10/05 13:45:00 0
#> 2 2000/10/05 13:50:00 1
#> 3 2000/10/05 13:55:00 0
#> 4 2000/10/05 23:55:00 0
#> 5 2000/10/06 00:00:00 0
#> 6 2000/10/06 00:05:00 0
#Resumen estadístico
summary(C4)
#> Fecha Valor..mm.
#> Length:1938620 Min. :0.000
#> Class :character 1st Qu.:0.000
#> Mode :character Median :0.000
#> Mean :0.013
#> 3rd Qu.:0.000
#> Max. :9.100
#> NA's :182451.4 Instalación de las librerías necesarias
Recuerda que R se potencializa a través de librerias o paquetes que ayudan a complementar las funciones básicas del programa. Para este clase necesitaremos 3 librerías que si aún no las has usado es importante que las instales previamente.
- librería
zoo: Análisis y manipulación de series temporales - librería
dplyr: Manipulación de datos de forma rápida y sencilla - librería
lubridate: Simplifica el trabajo con fechas y horas - librería
ggplot2: Producción de gráficos
1.5 Empecemos
En este laboratorio trabajaremos mucho con fechas por lo que es importante que el programa comprenda que la comuna 1 no es una cadena de texto sino una fecha.
Revisa como se está dando los datos de fecha, observa que sigue este formato:año/mes/día hora:minuto:segundo
#convertir la columna 1 a tipo fecha con as.POSIXct
C4[,1]<-as.POSIXct(C4[,1],format='%Y/%m/%d %H:%M:%S')Ahora es momento de depurar la serie, como pimer paso buscaremos fechas y horas que puedan estar repetidas.
Recuerda la función which() nos devuelve la posición de los elementos que cumplen con una condición. Mientras que la función duplicated()identifica filas duplicadas
La intención de esta sección es encontrar las posiciones de los elementos duplicados y con un condicional borrar esas posiciones si y unicamente si existieran datos duplicados, esto se comprueba cuando el vector borrar tiene una longitud mayor a cero, es decir dentro de este vector se alojan datos
#Borrar Duplicados
borrar <- which(duplicated(C4[,1]))
if (length(borrar) > 0) {
C4 <- data.frame(C4[-borrar,])
}
#Comprobemos cuantos datos se encontraban duplicados
# y Con cuantos datos quedó la serie
length(borrar)
#> [1] 10201
nrow(C4)
#> [1] 1928419Sigamos depurando la serie. Ahora vamos a rellenar huecos temporales con NA, ese paso es muy importante ya que pueden existir periodos de tiempo en los que no se hayan realizado resgistro de datos. Al no contar con un registro continuo de fechas, se generarían intervalos con datos agregados con saltos temporales que no reflejan la realidad de la serie de datos.
Antes de rellenar los espacios temporales con NA, vamos a determinar la fecha de inicio y fin de la serie de datos y convertiremos los datos a series temporales
Ahora con la función seq()crearemos una secuencia que empiece y termine en las fechas antes establecidas y tenga la misma escala temporal de los datos, es decir 5 minutos.
indice<-seq(start,end,by="5 min")Ahora tranformemos estos datos a series temporales con la función zoo() de la librería Zoo
Recuerda que para crear una serie temporal el primer argumento son los datos y el segundo argumento son las fechas.
Cuando creamos la serie temporal de control, con todas las fechas continuas, el primer argumento rep(NA,length(indice)) permite crear un vector con NA de la misma longitud que el número de fechas
A través de la función merge() se une las dos series (datos reales y serie con todos los tiempos posibles cada 5 minutos), esto permite rellenar huecos temporales con NA
datos_z <- merge(control_z,C4_z)
head(datos_z,15)
#> control_z C4_z
#> 2000-10-05 13:45:00 NA 0
#> 2000-10-05 13:50:00 NA 1
#> 2000-10-05 13:55:00 NA 0
#> 2000-10-05 14:00:00 NA NA
#> 2000-10-05 14:05:00 NA NA
#> 2000-10-05 14:10:00 NA NA
#> 2000-10-05 14:15:00 NA NA
#> 2000-10-05 14:20:00 NA NA
#> 2000-10-05 14:25:00 NA NA
#> 2000-10-05 14:30:00 NA NA
#> 2000-10-05 14:35:00 NA NA
#> 2000-10-05 14:40:00 NA NA
#> 2000-10-05 14:45:00 NA NA
#> 2000-10-05 14:50:00 NA NA
#> 2000-10-05 14:55:00 NA NAUna vez hemos depurado es momento de empezar a agregar los datos. Agreguemos los datos de precipitación a una escala temporal diaria.
Como primer paso se realizará un índice temporal, este índice nos indicará las fechas y horas a las cuales se cumple la escala temporal a la cual se requiere obtener los datos, por ejemplo:
Si queremos datos diarios requerimos resultados de la siguiente manera:
- 2000-10-05 13:45:00
- 2000-10-06 13:45:00
- 2000-10-07 12:45:00
Tenemos 2 opciones para realizar los mismo, observa que el primer código es mucho más corto ya que es una función establecida de as.POSIXct, sin embargo el tiempo que toma correr está línea es elevado. Para tener conocimiento de esta opción se ha colocado en la codificación pero se la mantendrá comentada. Es importante mencionar que cuando se trabaja con fechas es fundamental tener en cuenta la zona horaria en la que se está trabajando.
#ind_24h <- as.POSIXct(cut(index(datos_z), breaks = "days"), tz = "America/Bogota")La segunda forma de crear el índice tiene como base que cada fecha es el número de segundo transcurridos desde 1 de enero de 1970, Luego, esos segundos se dividen por el número de segundos que tiene la escala temporal a la que se quiere agrupar (en este caso 24 horas), y se redondea hacia arriba al número entero más cercano. Esto permite que todas las mediciones en este caso caigan en el día siguiente más próximo. Después, multiplicamos nuevamente por los segundos de un día para volver a tener un valor en segundos y sumamos estos segundos a la fecha base “1970-01-01” para tener la fecha completa pero en múltipos de 24 horas en este caso. Finalmente recuerda la importancia de la zona horaria
ind_24hr <- as.POSIXct(strptime("1970-01-01", "%Y-%m-%d") + ceiling(as.numeric(index(datos_z))/(24*60*60))*(24*60*60),
tz = "America/Bogota")Ya con el indice listo, indicándonos la fecha y hora hasta donde se agregarán los datos, usaremos la función aggregate()en donde puedes observar tres componentes, el primero es la data a trabajar, el segundo el parámetro de agrupación o columna de agrupación, y el tercero la función segun la cual se agrupará.
En resumen: Agrega (función: suma) los datos (datos_z) cada 24 horas según el nuevo índice.
zoo24hr_sum <- aggregate(datos_z,ind_24hr,function(x) round(sum(x,na.rm = F),1))
#importante No ignora los NA (na.rm = FALSE),
#por lo tanto si hay NA en un intervalo el total es NA.Listo tenemos los mismo datos de partida en otra escala temporal, ahora transformemos los datos a un Data Frame para visulaizar más fácil.
df24hr = data.frame(index(zoo24hr_sum),zoo24hr_sum)
df24hr_t = df24hr[,-2] #elimina la columna control_z
colnames(df24hr_t) = c("date","precipitation")
#visualicemos los últimos 20 días
tail(df24hr_t)
#> date precipitation
#> 2022-12-28 2022-12-28 4.5
#> 2022-12-29 2022-12-29 0.0
#> 2022-12-30 2022-12-30 0.0
#> 2022-12-31 2022-12-31 0.2
#> 2023-01-01 2023-01-01 4.8
#> 2023-01-02 2023-01-02 18.9Ahora agreguemos a precipitación mensual (con este tipo de datos trabajabamos el semestre anterior), utilizaremos la función format(), esta función nos permitirá de cada fecha extraer en este caso el mes y año.
Posteriormente usaremos la función aggregate(), bajo las mismas condiciones que ya revisamos.
Obseva que los datos que usamos, para obtener precipitación mensual, son los datos de precipitación cada 24 horas.
df24hr_t$mensual = format(as.Date(df24hr_t$date), "%Y-%m")
data_mensual = aggregate(precipitation ~ mensual,df24hr_t,sum)Grafiquemos la precipitación para diferentes esclas temporales
# Escala Temporal de 5 minutos
plot_5min = ggplot(C4, aes(x=Fecha, y=Valor..mm.))+
geom_step()+
theme_bw() +
labs (title="Precipitación [mm]", x= NULL, y=NULL)+
theme(plot.title = element_text(size = 20,hjust = 0.5))
print(plot_5min)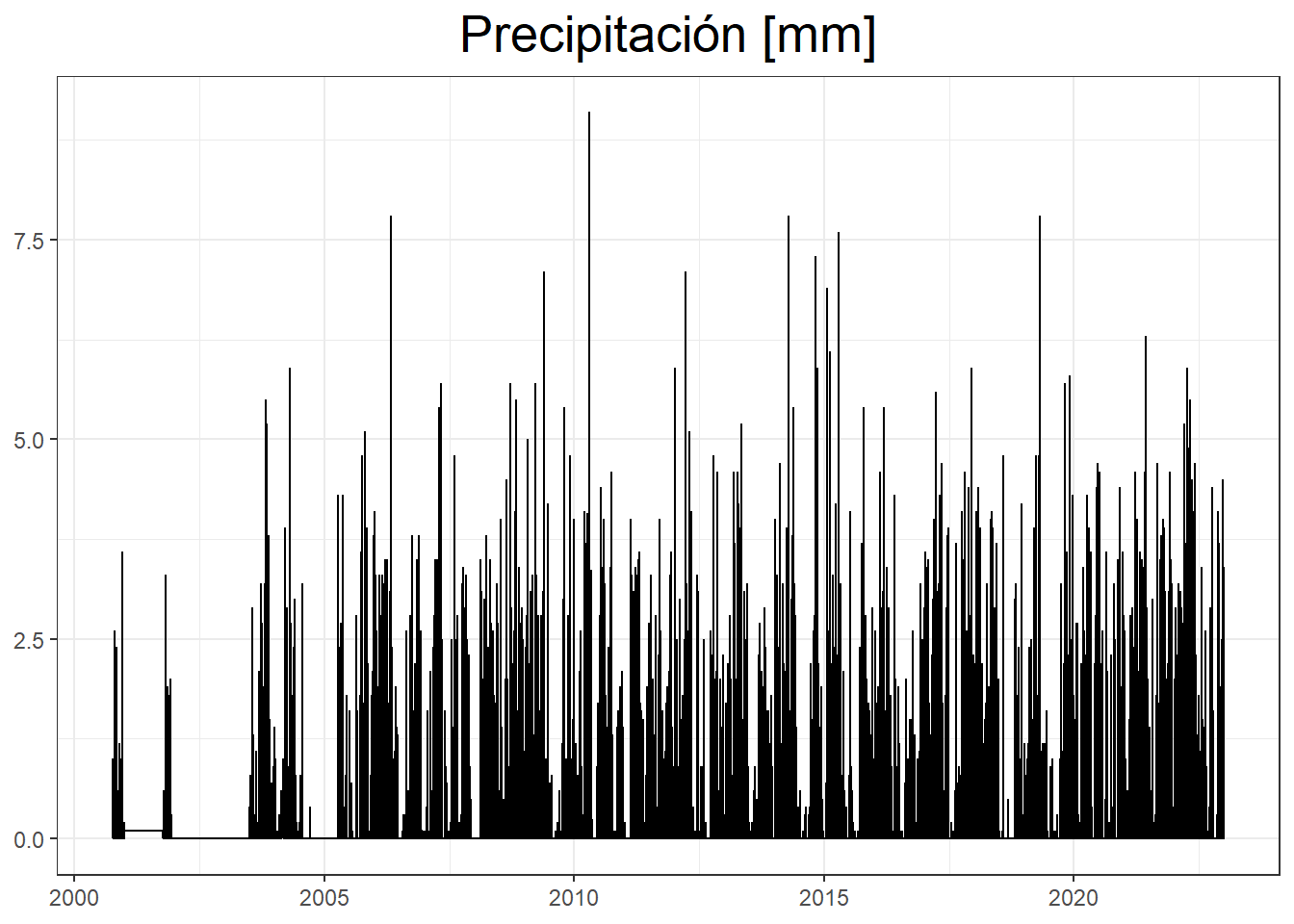
# Precipitación Diaria
plot_24hr = ggplot(df24hr_t, aes(x=date, y=precipitation))+
geom_step()+
theme_bw() +
labs (title="Precipitación [mm]", x= NULL, y=NULL)+
theme(plot.title = element_text(size = 20,hjust = 0.5))
print(plot_24hr)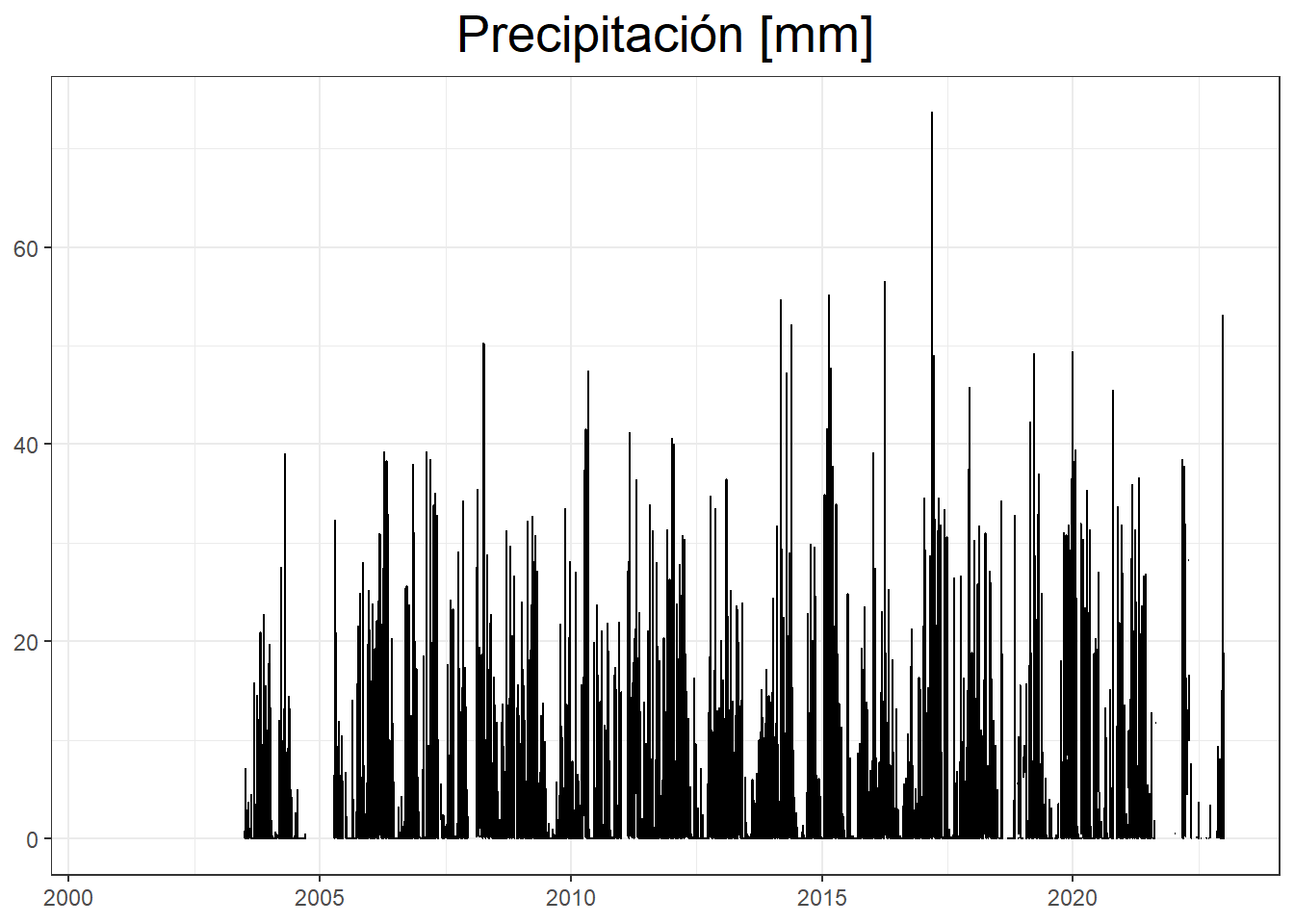
# Precipitación Mensual
data_mensual$mensual <- as.Date(paste0(data_mensual$mensual, "-01"))
plot_mensual = ggplot(data_mensual, aes(x=mensual, y=precipitation))+
geom_step()+
theme_bw() +
labs (title="Precipitación [mm]", x= NULL, y=NULL)+
theme(plot.title = element_text(size = 20,hjust = 0.5))
print(plot_mensual)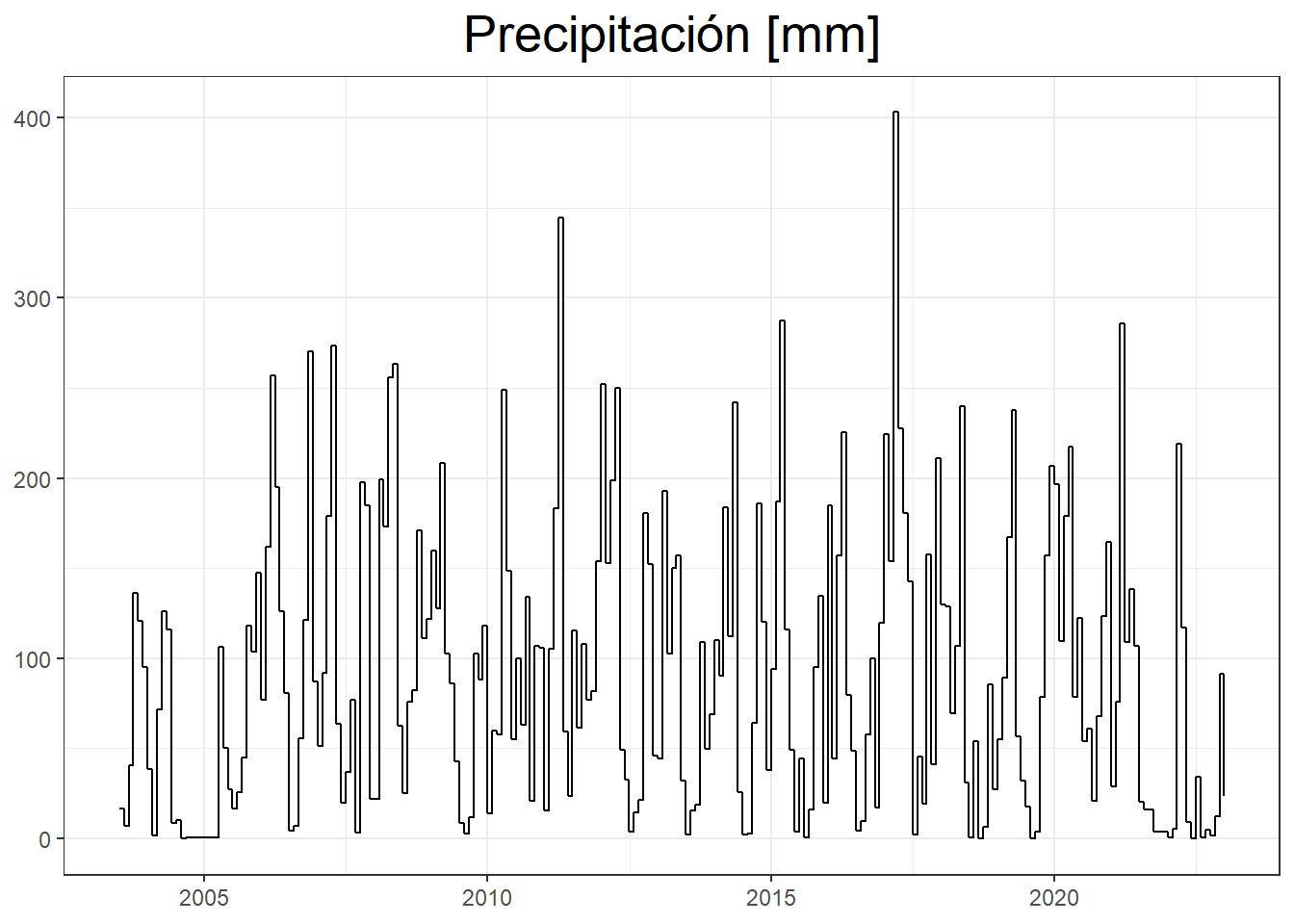
1.6 📝 TRABAJO AUTÓNOMO
Parte 1
En la parte 1 del taller se obtendrá datos de precipitación a diferentes escalas de tiempo. El taller se entregará de manera individual, a través del aula virtual en formato pdf y se utilizará los mismos datos trabajados en clase, obteniendo los siguientes resultados:
- Precipitación máxima anual con duración de 30 min, 1 hora, 2 horas, 6 horas, 12 horas y 24 horas.
Parte 2 En la parte 2 del taller se obtendrá datos de caudal a diferentes escalas de tiempo. El taller se entregará de manera individual, a través del aula virtual en formato pdf y se utilizará el archivo “Datos caudal Jatuhuaycu”, que se encuentra en la carpeta Documentos de repositorio de Github; obteniendo los siguientes resultados:
- Caudal mensual
- Gráfico de la serie temporal correspondiente al caudal mensual obtenido a partir de la base de datos
El taller deberá ser entregado el día y hora acordada en formato pdf, a través del aula virtual