Capítulo 2 Introducción a las distribuciones de probabilidad en R
2.1 Objetivo de la práctica
Comprender el uso básico de funciones de distribuciones de probabilidad en R como preparación para su aplicación en hidrología
2.2 Resultados de la práctica
Generar, visualizar e interpretar datos siguiendo una distribución de probabilidad en R, calculando densidades, probabilidades acumuladas y cuantiles, y relacionando estos resultados con la ocurrencia de eventos hidrológicos
2.3 ¿Que datos usaremos en la clase?
Para esta práctica se utilizarán los registros de precipitaciones máximas de la estación M0003–Izobamba (Código P16) como referencia. No trabajaremos directamente con los datos reales, sino que generaremos datos aleatorios que sigan una distribución específica. Estos datos simulados se caracterizarán usando las estadísticas de la serie real de la estación.
2.4 Instalación de las librerías necesarias
Para este clase necesitaremos 2 librerías que si aún no las has usado es importante que las instales previamente.
- librería
readxl: Lectura de datos tipo xlsx - librería
texmex: Ajuste de distribuciones de probabilidad
2.5 Empecemos
Como primer paso generaremos datos aleatorios que cumplan con una distribución; en esta clase utilizaremos la distribución de gumbel (distribución generalizada de valores extremos); para generar estos datos la función rnombre_de_la_funciónrequiere de 3 atributos: el primero es la cantidad de números que se quiere generar; el segundo y el tercero tiene gran relevancia ya que corresponden a la caracterización estadística (Tendencia central: Media y Dispersión: Desviación estandar)
# 10 datos aleatorios con media de 5 y varianza de 2
rgumbel(10,mu=5,sigma =2)
#> [1] 6.345970 10.084366 2.281180 4.574049 6.176757
#> [6] 3.610421 6.893855 6.393778 10.420025 3.646439Ahora generemos 1000 valores aleatorios que cumplan con una distribución de gumbel y estén caracterizados con la estadística de los datos de precipitaciones máximas de la estación Izobamba
Primero debemos cargar el archivo de datos
#Carguemos y almacenemos el archivo
max_preci<-read_excel("./Documentos/Precipitacion_maxima_IZOBAMBA.xlsx",
skip = 1 )
head(max_preci)
#> # A tibble: 6 × 10
#> Year d5 d10 d15 d20 d30 d60 d120 d360
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1962 9 14.8 12.8 13.5 14.1 16.8 20.4 27
#> 2 1963 9.2 10.5 12.3 14.3 17.5 23.6 25.6 28.8
#> 3 1964 9.5 12.2 14.7 15.6 20.1 24.3 33.2 37.8
#> 4 1965 8.8 13 16.2 17 20.4 35 39.4 44.4
#> 5 1966 9 11.1 12.9 15 18.5 19.3 22.2 25.8
#> 6 1967 6.5 7.2 8.5 10 14 20.8 24.8 28.2
#> # ℹ 1 more variable: d1440 <dbl>Una vez cargada la información con la que caraterizaremos los datos aleatorios, realicemos un proceso muy similar al anterior, sin embargo en el segundo atributo utilizaremos la función mean()aplicada a la serie de precipitación máxima con duración de 1440 min para obtener la media de esa columna y en el tercer atributo la función sd() aplicada a la serie de precipitación máxima con duración de 1440 min para obtener la desviación estandar para obtener la media de esa columna.
a<-rgumbel(1000,mu= mean(max_preci$d1440), sigma = sd(max_preci$d1440))
# Realicemos un histograma de estos valores
hist(a) 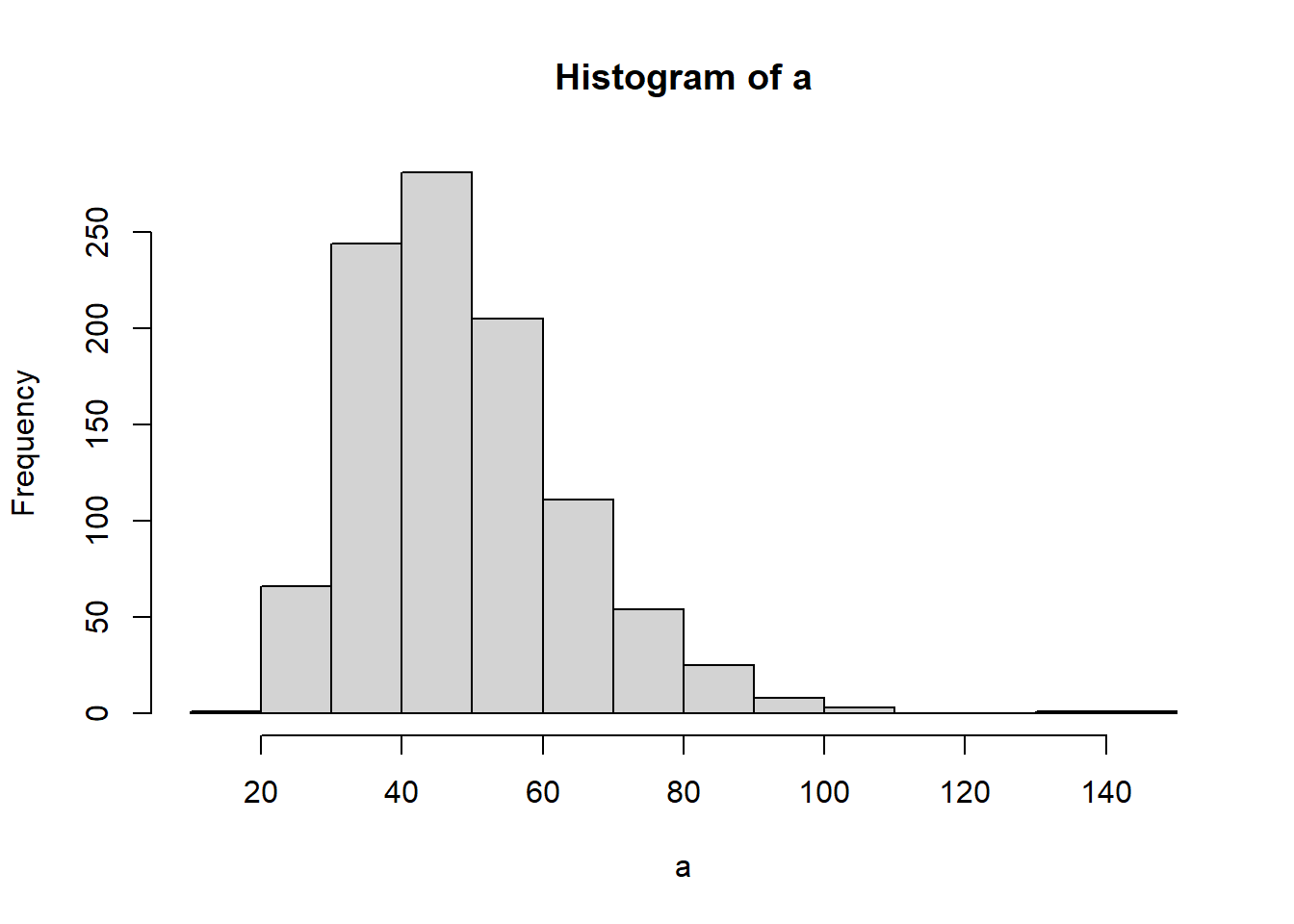
¿Que representa un histograma? Representa un gráfico de frecuencias
Ahora hablemos de probabilidad y grafiquemos un histograma en donde le indiquemos a R que no queremos frecuencia.
hist(a, freq = F )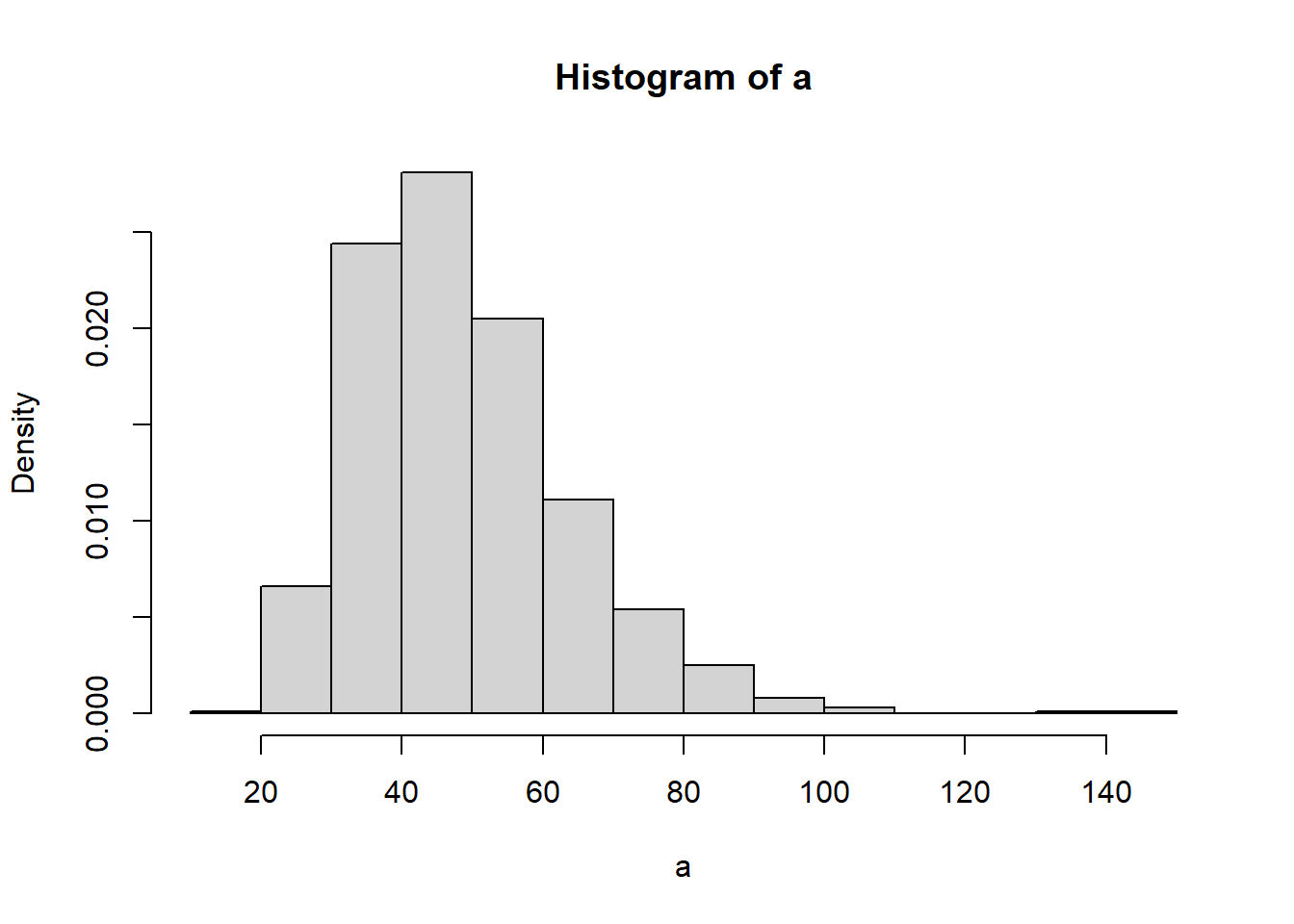
¿Qué representa este gráfico? Representa una funcion de densidad o probabilidad f(x)
Entonces ahora hablemos de como generar funciones de Densidad o probabilidad f(x) con la ayuda de R. Para obtener un función de densidad utilizaremos dnombre_de_la_función y declararemos tres componentes, el primero el valor para el que quiero obtener la densidad o probabilidad y el segundo y tercer componente será la caracterización estadística de la que ya hemos hablado
Grafiquemos para tener una mejor pespectiva de lo que estamos realizando. Estamos generando un gráfico simple de puntos en donde las coordenadas de las x son los datos aleatorios que cumplen con la distribución y las coordenadas de las y son la densidad o probabilidad de cada uno de los datos
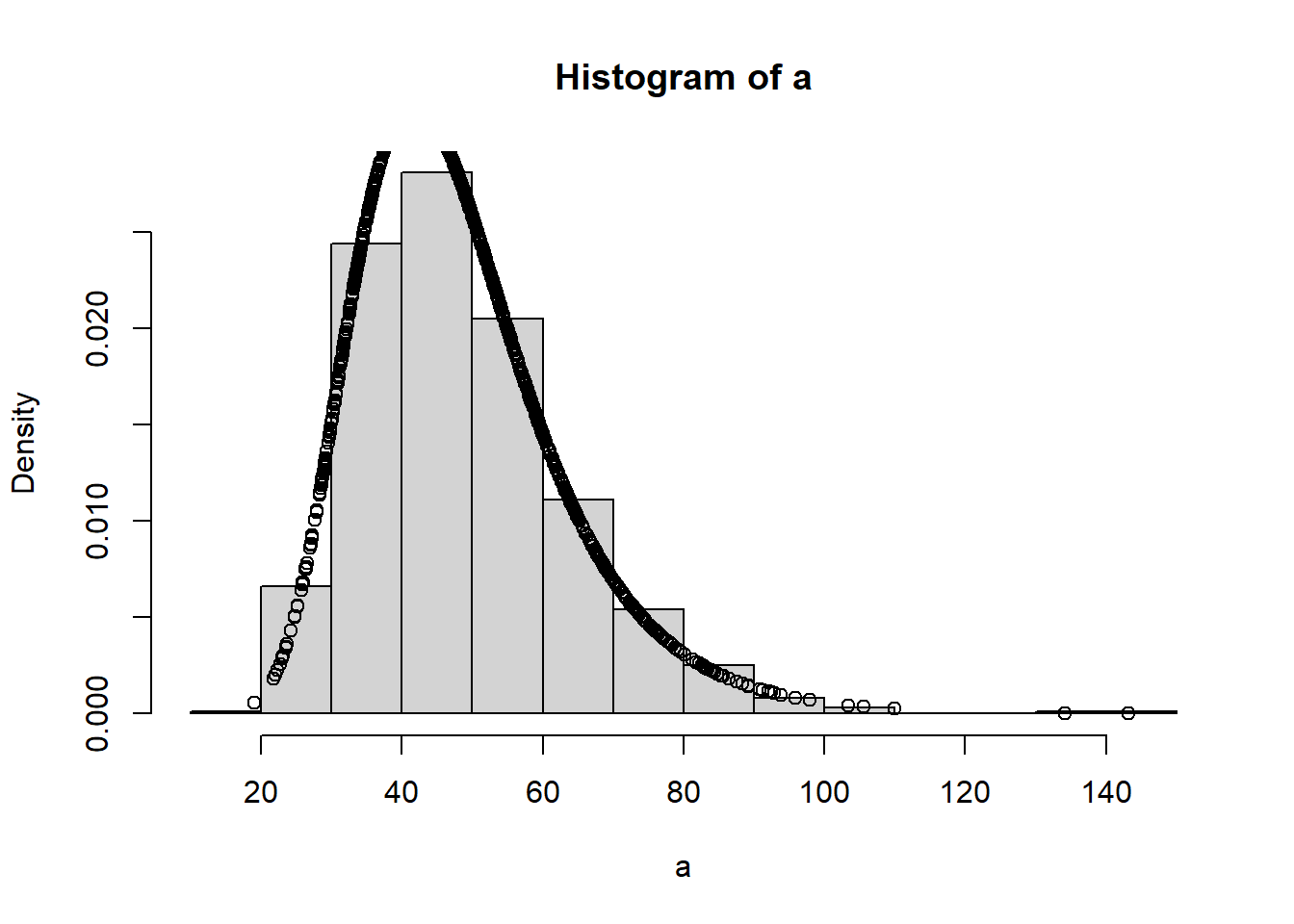
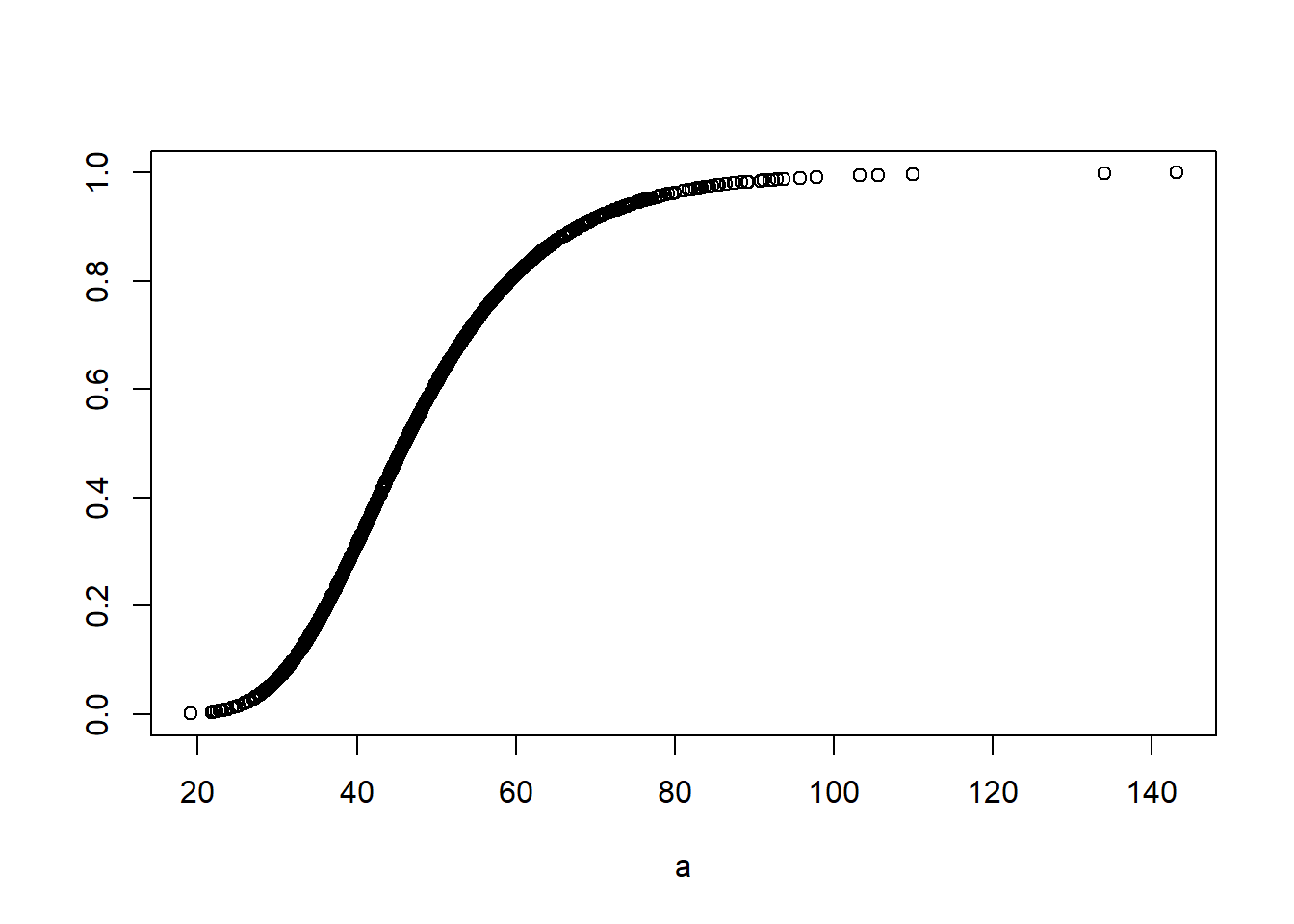
Ahora respondamos a la pregunta: ¿Cual es la probabilidad de ocurrencia P(x>valor)? para llegar a la solución es necesario hablar de Funcion de distribución F(x). Para obtener un función de densidad utilizaremos pnombre_de_la_función en donde debemos dejar claro tres cosas, la primera es el valor del que se quiere encontrar la probabilidad de ocurrencian y el segundo y tercer componente será la caracterización estadística.
Por el momento hemos analizado:Valor - Probabilidad: Evalúa la probabilidad de que se presente un valor
- Dato: Valor –> Resultado: Probabilidad
Grafiquemos para tener una mejor pespectiva de lo que estamos realizando. Estamos generando un gráfico simple de puntos en donde las coordenadas de las x son los datos aleatorios que cumplen con la distribución y las coordenadas de las y son la probabilidad de ocurrencian de cada uno de los datos. Es decir estamos generando un gráfico de densidad o probabilidad acumulada
Finalmente analicemos: Probabilidad - Valor: Que valor está encadenado a una probabilidad
- Dato: Probabilidad –> Resultado: Valor
Pidamosle a R que nos entregue el cuantil que acumula la probabilidad a través de qnombre_de_la_función en donde debemos indicarle la probabilidad acumulada de la que queremos conocer el cuantil y la caracterización estadística.