Capítulo 4 Curvas de Intensidad, Duración y Frecuencia
4.1 Objetivo de la práctica
Comprender la relación entre intensidad, duración y frecuencia de las precipitaciones, e identificar los datos necesarios y el procedimiento para construir curvas IDF
4.2 Resultados de la práctica
Reconocer los tipos de datos hidrológicos necesarios y cómo se organizan para la construcción de curvas IDF, comprendiendo conceptualmente cómo la intensidad, duración y frecuencia se relacionan
4.3 Instalación de las librerías necesarias
Para este clase necesitaremos 4 librerías que si aún no las has usado es importante que las instales previamente.
- librería
readxl: Lectura de datos tipo xlsx - librería
texmex: Ajuste de distribuciones de probabilidad - librería
fitdistrplus: Ajuste de distribuciones, evaluación y diagnóstico de ajustes - librería
ggplot2: Producción de gráficos - librería
reshape2: Nos permitirá usar la función melt
4.4 ¿Que datos usaremos en la clase?
Para esta práctica se utilizarán registros de precipitaciones máximas, de la estación M0003–Izobamba (Código P16). Sí, son los mismos datos que ocupamos la clase pasada, sin embargo hoy trabajaremos con todas las duraciones.
#Carguemos y almacenemos el archivo
max_preci<-read_excel("./Documentos/Precipitacion_maxima_IZOBAMBA.xlsx",
skip = 1 )
#Eliminemos la columa que indica el año
# La construcción de curvas IDF no depende
#de la cronología de los datos
max_preci<- max_preci[,-1]
head(max_preci)
#> # A tibble: 6 × 9
#> d5 d10 d15 d20 d30 d60 d120 d360 d1440
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 9 14.8 12.8 13.5 14.1 16.8 20.4 27 33.6
#> 2 9.2 10.5 12.3 14.3 17.5 23.6 25.6 28.8 36
#> 3 9.5 12.2 14.7 15.6 20.1 24.3 33.2 37.8 36
#> 4 8.8 13 16.2 17 20.4 35 39.4 44.4 38.4
#> 5 9 11.1 12.9 15 18.5 19.3 22.2 25.8 28.8
#> 6 6.5 7.2 8.5 10 14 20.8 24.8 28.2 364.5 Empecemos
Las curvas IDF relacionan la intensidad, la duración y la frecuencia de las precipitaciones. En los datos que tenemos, se observa que la duración está explícitamente registrada y la intensidad puede obtenerse implícitamente, sin embargo, aún no se ha asociado la información disponible con la frecuencia correspondiente
Mira este ejemplo de curvas IDF e identifica con que se relaciona la frecuencia.
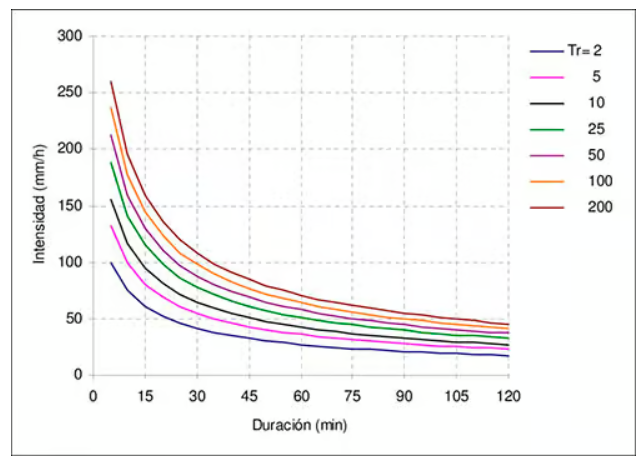
(#fig:Curva IDF)Ejemplo de Curva IDF
La frecuencia de una precipitación se relaciona directamente con su periodo de retorno, que indica el intervalo de tiempo promedio esperado entre eventos de igual o mayor magnitud.
Los datos disponibles ya están vinculados a un periodo de retorno, como se analizó en la clase anterior. Sin embargo, para la construcción de las curvas IDF nos centraremos en periodos de retorno seleccionados previamente y, a partir de estos y de la probabilidad asociada a cada periodo, estimaremos las precipitaciones correspondiente.
¿Te suena familiar lo que haremos? Sí, es aplicar lo que aprendimos la clase pasada. Sin embargo hoy aprenderemos a realizar este proceso más eficiente ya que trabajaremos con muchos datos.
Vamos a trabajar con funciones recuerda: una función es un conjunto de instrucciones, de esta forma, es posible escribir un bloque de código y ejecutarlo para distintos datos.
Para crear una función se usa la palabra function y se debe tener dos componentes muy importantes:
1. Los parámetros: los parámetros son los “datos” de entrada que empleará la función y lo pongo entre comillas por que a estos parámetros aun no se les ha asignado datos, son solo nombres que posteriormente ocuparán la información que queramos operar.
2.Después viene el código de la función entre {}
A la función le pediremos que ajuste los datos a dos distribuciones distintas y que, además, evalúe la bondad de ajuste para cada una de ellas.
ajuste<- function(col){
G <- fitdist(col, "gumbel",
start=list(mu=mean(col), sigma=sd(col)))
ln<-fitdist(col, "lnorm")
legend<- c("Gumbel","Lognormal")
gofstat(list(G,ln),fitnames = legend)
}Ahora aplicaremos la función a cada una de las duraciones utilizando apply(), lo que permite recorrer el data frame y devolver un vector con el resultado de F(x) para cada elemento. apply nos pedirá tres variables, la primera es el data frame a evaluar, la segunda es la opción de recorrer fila por fila o columna por columna (en nuestro caso columna por columna, es decir opción 2) y finalmente la función a ejecutarse.
apply(max_preci,2,ajuste)
#> $d5
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.1710791 0.1848619
#> Cramer-von Mises statistic 0.3257778 0.3764148
#> Anderson-Darling statistic 1.9390891 2.2167588
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 218.0438 218.1712
#> Bayesian Information Criterion 221.6571 221.7846
#>
#> $d10
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.1035842 0.09805726
#> Cramer-von Mises statistic 0.0484098 0.03950789
#> Anderson-Darling statistic 0.3004972 0.25313539
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 234.2554 233.6519
#> Bayesian Information Criterion 237.8687 237.2652
#>
#> $d15
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.09246889 0.09512869
#> Cramer-von Mises statistic 0.07607875 0.06734267
#> Anderson-Darling statistic 0.46705371 0.40276195
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 253.4643 252.1882
#> Bayesian Information Criterion 257.0776 255.8015
#>
#> $d20
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.09245389 0.08438802
#> Cramer-von Mises statistic 0.07231011 0.05983944
#> Anderson-Darling statistic 0.49958109 0.42013731
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 268.0695 266.6163
#> Bayesian Information Criterion 271.6828 270.2296
#>
#> $d30
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.1288841 0.1220199
#> Cramer-von Mises statistic 0.1432684 0.1149902
#> Anderson-Darling statistic 0.7609195 0.6058631
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 277.1214 275.1273
#> Bayesian Information Criterion 280.7347 278.7406
#>
#> $d60
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.07708190 0.06375480
#> Cramer-von Mises statistic 0.04882545 0.03866144
#> Anderson-Darling statistic 0.34126020 0.27968867
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 303.9785 303.1487
#> Bayesian Information Criterion 307.5919 306.7620
#>
#> $d120
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.06918579 0.08075970
#> Cramer-von Mises statistic 0.03542140 0.03334073
#> Anderson-Darling statistic 0.25909911 0.22316386
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 316.3288 315.7086
#> Bayesian Information Criterion 319.9422 319.3220
#>
#> $d360
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.10094601 0.1280951
#> Cramer-von Mises statistic 0.07279252 0.1283005
#> Anderson-Darling statistic 0.47943579 0.7724985
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 320.8431 323.4638
#> Bayesian Information Criterion 324.4564 327.0772
#>
#> $d1440
#> Goodness-of-fit statistics
#> Gumbel Lognormal
#> Kolmogorov-Smirnov statistic 0.1639417 0.1804595
#> Cramer-von Mises statistic 0.1485403 0.1895772
#> Anderson-Darling statistic 0.7839431 0.9974622
#>
#> Goodness-of-fit criteria
#> Gumbel Lognormal
#> Akaike's Information Criterion 338.5845 340.3576
#> Bayesian Information Criterion 342.1978 343.9709A partir de los resultados de las pruebas de bondad de ajuste, seleccionaremos la distribución de probabilidad que mejor se ajusta a nuestros datos y, en función de ello, construiremos dos data frames según el mejor ajuste
Recuerda lo que hablamos de periodo de retorno y su vínculo con la probabilidad, por que ha llegado el momento de usarlo.
Creemos un vector que contenga los periodos de retorno que nos interesan analizar y posteiormente la probabilidad de no ocurrencia
#Periodo de retorno a analizar
TR<- c(2,5,10,25,50,75,100)
#Probabilidad de no ocurrencia
#ligada al periodo de retorno
p<- 1-(1/TR)Ahora que se ha determinado la probabilidad asociada y se ha identificado la distribución de probabilidad que mejor representa cada serie de datos, el siguiente paso consiste en realizar el ajuste de los datos a dicha distribución. Para ello se implementará una función en R, que luego aplicaremos de manera sistemática con apply() a toda la base de datos. Ojo en esta sección por que deberás corregirla, en esta práctica, utilizaremos la distribución de Gumbel para todos los casos a modo de ejemplo; sin embargo, lo correcto sería aplicar a cada serie la distribución que efectivamente ofrezca el mejor ajuste.
#Función para distribución Gumbel para todas las duraciones
preci_cal<- function(col){
qgumbel(p,mu = mean(col),sigma = sd(col))
}
#Ejecución de la función
m1<- data.frame(apply(df_gumbel,2,preci_cal))
m2<- data.frame(apply(df_lognormal,2,preci_cal))
## Combinar m1 y m2 en un solo data frame y reordenar las columnas
data <- cbind(m1, m2)[, c(1, 6, 2, 7, 8, 9, 3, 4, 5)]
head(data)
#> d5 d10 d15 d20 d30 d60
#> 1 8.441238 11.99450 15.10047 18.19092 21.84944 28.78101
#> 2 11.159562 15.63346 19.36265 23.20012 27.40385 36.72146
#> 3 12.959328 18.04277 22.18458 26.51664 31.08134 41.97873
#> 4 15.233338 21.08695 25.75010 30.70708 35.72787 48.62130
#> 5 16.920328 23.34529 28.39520 33.81578 39.17493 53.54914
#> 6 17.900872 24.65792 29.93264 35.62268 41.17849 56.41339
#> d120 d360 d1440
#> 1 33.44868 38.70312 46.03983
#> 2 42.67043 49.63261 59.23381
#> 3 48.77604 56.86889 67.96938
#> 4 56.49049 66.01194 79.00679
#> 5 62.21351 72.79477 87.19497
#> 6 65.53994 76.73721 91.95425Hasta ahora, hemos organizado los datos de precipitación según su duración y periodo de retorno. A continuación, calcularemos la intensidad de precipitación (cantidad de lluvia por unidad de tiempo). Utilicemos la función sweep(X, MARGIN, STATS, FUN) que aplica una operación entre X y STATS a lo largo de la margen indicada, por tanto **sweep(data, 2, duraciones, “/”)*60**, que divide cada columna de precipitación por su duración correspondiente y multiplica por 60 convirtiendo los valores a intensidad en mm/h.
La función melt transforma la tabla de un formato “ancho” a un formato “largo”, de manera que cada fila representa un único valor de intensidad, junto con su duración y el periodo de retorno correspondiente.Esto facilita tanto el análisis estadístico como la creación de gráficos.
rownames(data) <- paste0("T", TR)
duraciones <- as.numeric(gsub("d", "", names(data)))
int <- melt(
cbind(sweep(data,2,duraciones,"/")*60,
TR = as.numeric(gsub("T", "", rownames(data)))),
id.vars = "TR",
variable.name = "duracion",
value.name = "intensidad"
)
int$duracion <- as.numeric(gsub("d", "", int$duracion))
head(int,10)
#> TR duracion intensidad
#> 1 2 5 101.29486
#> 2 5 5 133.91474
#> 3 10 5 155.51194
#> 4 25 5 182.80006
#> 5 50 5 203.04394
#> 6 75 5 214.81046
#> 7 100 5 223.13835
#> 8 2 10 71.96699
#> 9 5 10 93.80078
#> 10 10 10 108.25665Además observa que usamos la función gsub() que funciona de la siguiente manera gsub(pattern, replacement, x) en donde:
pattern → el texto o expresión regular que quieres encontrar.
replacement → el texto que lo reemplazará.
*x → el vector de caracteres donde se aplica la función.
Muy bien ya tenemos todos los datos necesarios para poder armar la ecuación de Intensidad - Duración y Frecuencia, pero antes debes recordar dos cosas: logaritmos y regresión lineal múltiple. El primero tema lo revisaremos rápidamente (algunas reglas importantes), para el segundo tema te dejo un video muy corto y fácil de entender.
<
Oserva este modelo de ecuación de curva IDF \(I = \frac{K \, T^{m}}{t^{n}}\) en donde:
- I = Intensidad [mm/h]
- T = Periodo de retorno [años]
- t = tiempo de duración [minutos]
- k,m,n = constantes
Si observamos la ecuación, notamos que contamos con datos de intensidad, periodo de retorno y tiempo de duración; por lo tanto, el objetivo será determinar las constantes. Para ello, se requiere aplicar una regresión lineal múltiple, dado que tenemos una variable dependiente y dos variables independientes. Ahora hagamos otra observación, esta ecuación no se ve lineal, pues ha llegado el momento de utilizar los logaritmos.
Apliquemos logartimo a los dos lados e intenta llegar a este resultado: \(log I = \log K + m \log T - n \log t\)
Renombremos a los componentes de la ecuación para que quede más evidente la ecuación lineal múltiple \(y = a_{0} + a_{1}X_{1} + a_{2}X_{2}\)
Donde:
- \(Y = log I\)
- \(a_{0} = log K\)
- \(a_{1} = m\)
- \(X_{1} = log T\)
- \(a_{2} = n\)
- \(X_{2} = log t\)
Como vimos es necesario transformar nuestra data a logaritmos. Y armar el modelo
log_data<- log(int,base = 10)
colnames(log_data) = c("log_tr","log_t","log_i")
# Modelo lineal múltiple
modelo<- lm(log_i ~ log_tr + log_t, data = log_data)
# Resumen estadístico del ajuste del modelo
summary(modelo)
#>
#> Call:
#> lm(formula = log_i ~ log_tr + log_t, data = log_data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.14431 -0.05005 0.01167 0.05431 0.11305
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.59138 0.02893 89.56 <2e-16 ***
#> log_tr 0.17814 0.01486 11.98 <2e-16 ***
#> log_t -0.70835 0.01178 -60.12 <2e-16 ***
#> ---
#> Signif. codes:
#> 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.0696 on 60 degrees of freedom
#> Multiple R-squared: 0.9843, Adjusted R-squared: 0.9838
#> F-statistic: 1879 on 2 and 60 DF, p-value: < 2.2e-16
modelo$coefficients
#> (Intercept) log_tr log_t
#> 2.5913849 0.1781426 -0.7083488La instrucción summary(modelo) nos permite ver cómo se ajusta nuestro modelo de regresión lineal múltiple. Nos muestra si la variable dependiente tiene una relación significativa con las variables independientes y nos da indicadores de ajuste, como el R², que nos dice qué proporción de la variabilidad de la respuesta es explicada por el modelo (entre 0 y 1, donde valores más cercanos a 1 indican un mejor ajuste). Por otro lado, modelo$coefficients nos entrega los coeficientes estimados (intercepto y pendientes), que luego usamos para armar la ecuación final de la regresión.
# Asignación de variables establecidas
a0<- round(modelo$coefficients[1],3)
k<- 10^(a0)
a1<- round(modelo$coefficients[2],3)
a2<- round(modelo$coefficients[3],3)
r2<- round(summary(modelo)$r.squared,2)
#Ecuación Lineal
paste( "y = ",a0, "+ ", a1, "* x1","+ ", a2, "* x2", " R2=", r2)
#> [1] "y = 2.591 + 0.178 * x1 + -0.708 * x2 R2= 0.98"A partir de esta ecuación lineal, construye la ecuación IDF de la forma: \(log I = \log K + m \log T - n \log t\)
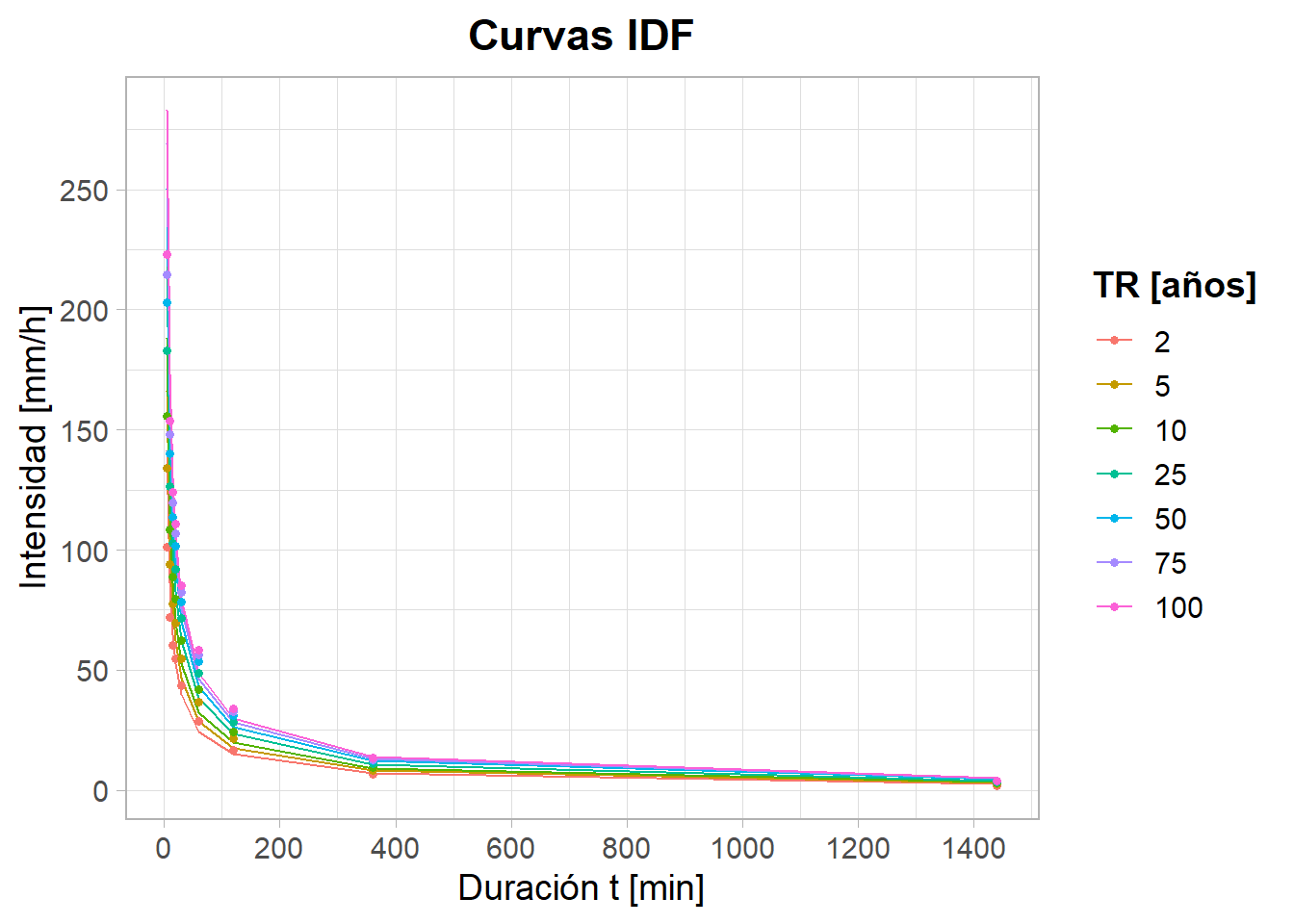
Probemos la ecuación que generamos, obtendremos intensidades a partir de periodos de retorno y duraciones conocidas (las mismas que vinimos trabajando durante la clase)
int$i_cal<-(k*(int$TR^a1))/(int$duracion^(-a2))
# Grafiquemos
int$TR_g<- factor(int$TR, levels = c('2', '5', '10', '25', '50',
'75', '100'))
ggplot(int, aes(x = duracion)) +
# Líneas sobre i_cal
geom_line(aes(y = i_cal, color = TR_g)) +
# Puntos sobre intensidad
geom_point(aes(y = intensidad, color = TR_g), size = 1.2) +
scale_y_continuous(breaks = seq(0, 300, by = 50)) +
scale_x_continuous(breaks = seq(0, 1600, by = 200)) +
labs(
x = "Duración t [min]",
y = "Intensidad [mm/h]",
color = "TR [años]",
title = "Curvas IDF"
) +
theme_light(base_size = 14) +
theme(
legend.position = "right",
legend.title = element_text(face = "bold"),
plot.title = element_text(face = "bold", hjust = 0.5)
)
4.6 📝 TRABAJO AUTÓNOMO
En este taller se obtendrá curvas de Intensidad, Duración y Frecuencia. El taller se entregará de manera individual y se utilizarán el archivo Datos_Taller_EPMAPS_RUMIPAMBA, que se encuentra en la carpeta Documentos de repositorio de Github, obteniendo los siguientes resultados:
Tabla de resultado de la prueba de bondad de Kolmogorov-Smirnov para las distribuciones de probabilidad (log-normal y Gumbel) que contenga (Ks y Ks crítico) y selección de la función de probabilidad empleada para cada duración de evento.
Precipitaciones calculadas, para cada duración de evento, con la distribución de probabilidad que tenga mejor ajuste.
Ecuaciones de Intensidad, duración y frecuencia IDF obtenida.
Gráfico de curvas IDF (observadas y calculadas)
El taller deberá ser entregado el día y hora acordada en formato pdf, a través del aula virtual.